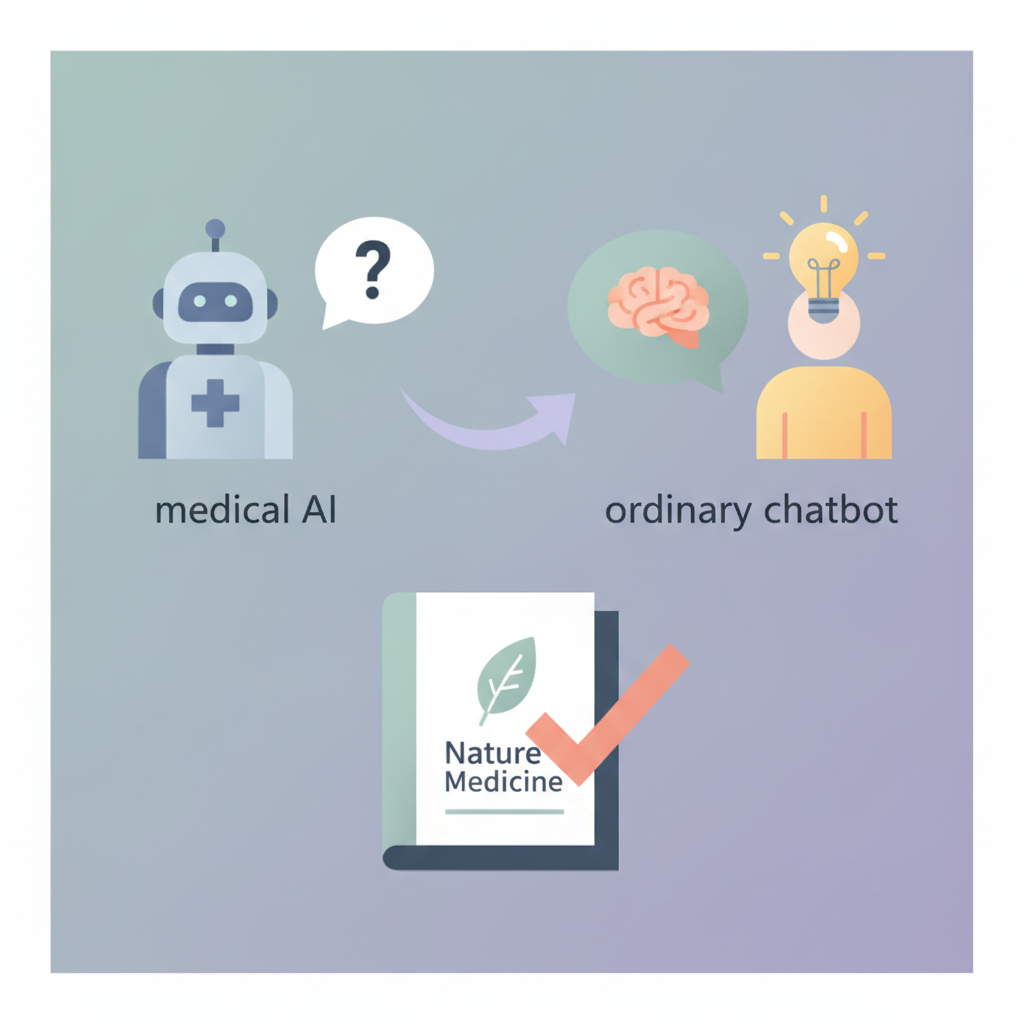
健康のことで気になることがあると、最近は検索エンジンの代わりにAIチャットボットに質問する方も増えているのではないでしょうか。一方で医療現場では、医師向けに特化した「専用の医療AIツール」が次々と登場しています。では、専門に作り込まれた医療AIと、私たちが日常的に使う汎用チャットボットでは、どちらが医学的な質問に正確に答えられるのでしょうか。2026年6月にNature Medicineに掲載された検証研究が、この問いに踏み込みました。
研究チームは、医師向けに設計された2つの臨床AIツール(OpenEvidenceとUpToDate Expert AI)と、汎用の最新大規模言語モデル3種(GPT-5.2、Gemini 3.1 Pro、Claude Opus 4.6)を、同じ土俵で比較しました。評価は3段階で行われています。第1段階は医師国家試験形式の知識を問うMedQAの500問、第2段階は臨床的な適切さを測るHealthBenchの500項目、そして第3段階は、実際の診療現場で医師がAIに投げかけた100件の匿名化された質問を集めたRCQ(Real Clinical Queries)と呼ばれるベンチマークです。RCQでは、12人の米国の臨床医が、どのAIの回答かを伏せた状態(盲検)で無作為に評価し、合計1,800件の回答が採点されました。
結果は予想を裏切るものでした。3つの評価すべてにおいて、汎用の最新モデルが、医療専用に作られたAIツールを上回る成績を示したのです。さらに印象的なのは、実際の臨床質問を扱ったRCQにおいて、専用の医療AIツールの回答品質が、一般的な検索エンジンのAI要約機能(Google検索のAI Overview)と同程度にとどまったという点です。評価にあたった臨床医たちも、専用ツールよりも汎用モデルの回答を好む傾向が示されました。
ただし、この結果をそのまま「専用医療AIは不要」と読み替えるのは早計だと考えられます。研究チーム自身が、ベンチマーク上の高得点と、実際の診療現場での使いやすさや安全性のあいだには隔たりがあると指摘しています。規制への適合、電子カルテとの連携、誤りが生じたときの責任の所在といった、点数には表れにくい要素が、実臨床では決定的に重要になるからです。テストで高得点を取ることと、現実の患者さんを安全に支えることは、必ずしも同じではありません。
この研究は、私たちが健康情報をAIに尋ねるときの向き合い方にも示唆を与えてくれます。第一に、最新の汎用チャットボットは、医学的な質問に対しても想像以上に的確な情報を返しうる、という点です。「医療専用」と銘打たれていないからといって、内容が劣るとは限りません。第二に、それでもAIの回答はあくまで出発点であり、最終的な判断を委ねる相手ではない、という点です。気になる症状があるときは、AIで得た情報を手がかりにしつつ、必ず医療機関で確認することが大切です。AIは賢い相談相手になりつつありますが、診断や治療の責任を負えるのは、今のところやはり人間の医療者です。便利さと限界の両方を理解したうえで、上手に付き合っていきたいものです。
出典 論文タイトル: General-purpose large language models outperform specialized clinical AI tools on medical benchmarks 掲載誌: Nature Medicine(2026年6月12日公開) DOI: 10.1038/s41591-026-04431-5
キバロクは予防医療×データの実装を支援します
こうした研究知見を、貴社の健康経営・健保事業・人間ドック施設の現場でどう使うか — 医師・医学博士×データサイエンティストが外部顧問として伴走します。まずは30分の無料相談から。
無料相談を予約する